¿Por qué no debes usar relaciones polimórficas?
La verdad no se como empezar este post, ya que el tema es muy delicado en el mundo de RubyOnRails y algo en Java, no quiero ofender a la comunidad, sino ayudarlos hacer un buen modelo de datos dentro de un Manejador de Bases de Datos Relacionales (RDBMS). Considero que primero debemos enterarnos que son las relaciones polimórficas, luego hablar de los problemas que conlleva y por último como podemos evitarlos.
¿Qué son las relaciones polimórficas?
Es una forma de relacionar muchas tablas con una sola mediante una única relación, esto se debe que programamos orientado a objetos y tratamos la base de datos de la misma forma, creando relaciones entre objetos, es una implementación de la librería (gema) ActiveRecord que compone el framework RubyOnRails. Depende del enfoque, esto nos puede traer un ahorro en el uso de tablas como mayor complicación del código.
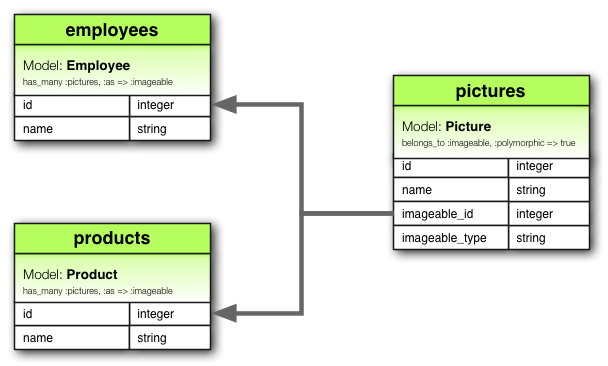
Como vemos en el modelo anterior, explica un caso hipotético de que una imagen puede estar relacionada con uno o varios productos y/o empleados.
El problema
La razón es muy simple, hasta el día de hoy NO hay un Manejador de Bases de Datos Relacionales que tenga un una restricción de integridad referencial para las relaciones polimórficas, y en el álgebra relacional no existe forma de representarlo. El día que uses MySQL u otro para tus cosas y tenga implementado esta funcionalidad y sea un software seguro, no habrá ningún problema.
Por otro lado, se crea una discusión ideológica llamada Object-relational impedance mismatch que es bastante interesante.
Al no existir una restricción que soporte este tipo de invento, nos encontramos con una serie de inconvenientes técnicos:
Se presenta una inconsistencia de datos porque no puede gestionarlos el RDBMS, y se tiende a delegar en la aplicación. El problema es que la aplicación se ejecuta en varios servidores, y los datos terminan en la base de datos quien tiene la última palabra si es valido o no, mientras que los servidores de aplicaciones por la concurrencia trabajan de forma aislada. Éste es uno de los típicos argumentos cuando no hay relaciones definidas dentro del RDBMS.
Por otro lado, las consultas se hacen más complicadas y difícil de mantener, porque puede que necesitemos consultas diferentes dependiendo del ROW, muestro un simple ejemplo:
SELECT *
FROM purchases p
LEFT OUTER JOIN shoes s ON s.id = p.item_id AND p.item_type = 'Shoe'
LEFT OUTER JOIN bags b ON b.id = p.item_id AND p.item_type = 'Bag'
WHERE p.id = 1;
Como vemos en la consulta anterior, debemos hacer LEFT OUTER JOIN por cada tabla “relacionada” para obtener una lista de todos los productos comprados, se puede simplificar mucho si usamos la siguiente forma:
SELECT *
FROM purchases p
JOIN items i ON i.id = p.item_id
WHERE e.id = 1;
Para poder distinguir si nuestro item es un Zapato o un Bolso u otra cosa, simplemente podemos implementar atributos, o ir más allá y usar EAV.
Por otro lado, a nivel de programación puede ser que sea mucho más simple, porque podemos usar una misma línea para buscar en muchas otras tablas, mientras con la forma tradicional de hacer relaciones puede dependiendo del caso generar más líneas de código.
La solución
Siempre hay una forma de hacerlo bien, vamos a usar el ejemplo anterior, podemos resolverlo de varias formas, siendo la segunda la mejor alternativas.
- Creamos una columna en la tabla pictures por cada tabla relacionada (employee_id y product_id).
- Creamos una columna (picture_id) en las tablas employees y products que se relaciona con la tabla pictures.
Quiero mostrar varios ejemplos, el primero sería una consulta SQL usando relaciones polimórficas, y el segundo ejemplo es usando la forma correcta de normalización:
SELECT *
FROM employees e
JOIN pictures p ON p.imageable_id = e.id AND p.imageable_type = 'Employee'
WHERE e.id = 1;
Como podemos observar la consulta es mucho más compleja por tener una condición más que evaluar.
SELECT *
FROM employees e
JOIN pictures p ON p.id = e.picture_id
WHERE e.id = 1;
En este caso es la representación correcta por un correcto modelo de datos. Una consulta SQL mucho más simple.
Conclusión
Hay mucha información por Internet con las practicas más idóneas, dejo algunos ejemplos:
- Practical Object Oriented Models In Sql
- Possible to do a MySQL foreign key to one of two possible tables?
Desde el punto de vista del desarrollador puede ser ventajoso, pero es un gran problema para la base de datos por romper la integridad, complejidad del mododelo y menor flexibilidad, debemos pensar en función de la calidad de nuestros datos y del producto que estamos ofreciendo. Esto me recuerda que “si alimentamos nuestro sistema con datos basura, los procesamos, y obtendremos datos basura”. No queremos esto verdad?